Relevanz oder Quantität?
Journalisten oder Wissenschaftler müssen an der Hürde der Gatekeeper und ihrer Qualitätskontrolle vorbei, wollen sie ihre Werke veröffentlichen. Es stellt sich die Frage, ob es solche Gatekeeper auch im Internet gibt. Clay Shirky (2005) sagt dazu: “The Web has an editor, it’s everybody”. Eine Qualitätskontrolle des Contents findet statt – jedoch erst nach seiner Veröffentlichung. Je mehr Nutzer ein Dokument taggen, desto mehr Relevanz scheint dieses Dokument für sie zu haben. Ist dies aber eine ernstzunehmende Qualitätskontrolle? Wird etwas zu „geprüfter“ Qualität, nur weil viele Leute dies so sehen? (Wenn viele Studenten bei einer Mathematikklausur die gleiche – falsche – Lösung bringen, wird diese nicht dadurch qualitativ wertvoll, sondern bleibt falsch. Quantität bedeutet nicht Qualität. Andererseits weist es in eine bestimmte Richtung, wenn viele Nutzer ein Stück Information mit stupid und ein anderes mit cool taggen. Dieser Content könnte für das Relevance Ranking verwertet werden.
// Peters, Isabella / Stock, Wolfgang G. 2008: Folksonomien in Wissensrepräsentation und Information Retrieval. Information - Wissenschaft & Praxis. 59(2008)2. S. 81
Glocalisation
We find community in networks, not groups (...) In networked societies: boundaries are permeable, interactions are with diverse others, onnections switch between multiple networks, and hierarchies can be flatter and recursive (...) Communities are far-flung, loosely-bounded, sparsely-knit and fragmentary. Most people operate in multiple, thinly-connected, partial comunities as they deal with networks of kin, neighbours, friend, workmates and organizational ties. Rather than fitting into the same group as those around them, each person his/her own personal community. (...) Huge increase(s) in speed (have) made door-to-door comunications residual, and made most communications place-to-place or person-to-person. (...) The household is what is visited, telephoned or emailed.
// Wellman, Barry 2001: Physical Place and Cyberplace: The Rise of Personalized Networking. In: International J. Urban and Regional research. Jg. 25. S 227-252. S. 233f
Ontologische Bodenlosigkeit
Das Leben in der Wissens-, Risiko-, Ungleichheits-, Zivil-, Einwanderungs-, Erlebnis- und Netzwerkgesellschaft verdichtet sich zu einer verallgemeinerbaren Grunderfahrung der Subjekte in den fortgeschrittenen Industrieländern: In einer "ontologischen Bodenlosigkeit", einer radikalen Enttraditionalisierung, dem Verlust von unstrittig akzeptierten Lebenskonzepten, übernehmbaren Identitätsmustern und normativen Koordinaten. Subjekte erleben sich als Darsteller auf einer gesellschaftlichen Bühne, ohne dass ihnen fertige Drehbücher geliefert würden. Genau in dieser Grunderfahrung wird die Ambivalenz der aktuellen Lebensverhältnisse spürbar. Es klingt natürlich für Subjekte verheißungsvoll, wenn ihnen vermittelt wird, dass sie ihre Drehbücher selbst schreiben dürften, ein Stück eigenes Leben entwerfen, inszenieren und realisieren könnten. Die Voraussetzungen dafür, dass diese Chance auch realisiert werden können, sind allerdings bedeutend. Die erforderlichen materiellen, sozialen und psychischen Ressourcen sind oft nicht vorhanden und dann wird die gesellschaftliche Notwendigkeit und Norm der Selbstgestaltung zu einer schwer erträglichen Aufgabe, der man sich gerne entziehen möchte. Die Aufforderung, sich selbstbewusst zu inszenieren, hat ohne Zugang zu der erforderlichen Ressourcen, etwas zynisches.
// Keupp, Heiner 2003: Identitätskonstruktion. Vortrag bei der 5. bundesweiten Fachtagung zur Erlebnispädagogik am 22.09.2003 in Magdeburg; Online im Internet: www.ipp-muenchen.de/texte/identitaetskonstruktion.pdf (29.06.2010)
Why People Choose Work Group Members?
In our study, people are choosing group members for future projects based on people’s reputation for competence. People may not actually know each other’s grades or the number of hours put in on previous projects, but it is clear that a reputation for competence is developed and circulates within the organization. Further, it is an important basis on which people develop their preferences for future group members. It is interesting to note that grade point average was not a significant predictor of being chosen as a team member. This may indicate that people do not choose others based on general indicators of competence or that information on grade point average and general competence circulate less freely in these groups or are harder to assess.
Finally, we hypothesized that people would choose others with whom they were already familiar for future work groups. This hypothesis was partially supported. But, our analysis indicates that familiarity alone is not adequate to generate a future work tie. During the course of project 1, people established working relationships with others in their group. These relationships varied over time, but on average, each person had either a strong or weak tie with each other member in his or her current group. Where there were strong ties, people elected to continue those relationships in future work groups. This is consistent with Kilduff’s (1990) finding that MBA students, when they look for jobs, want to work in the same companies as their friends. These data suggest that familiarity may lead to an awareness of whether or not an ongoing working relationship is effective. If a relationship is successful, then people are especially inclined to repeat it. This is consistent with our argument that people are seeking to reduce uncertainty in their choice of future group members. Although there may be better group members in the organization, people are choosing a “sure thing” rather than taking the risk of working with someone who has a work style and work ethic with which they do not have personal experience.
// Hinds, Pamela J. / Carley, Kathleen M. / Krackhardt, David/ Wholey, Doug 2000: Choosing Work Group Members: Balancing Similarity, Competence, and Familiarity In: Organizational Behavior and Human Decision Processes Vol. 81, No. 2, March, S.
![]()

Data Warehouse
Als Data Warehouse werden Systeme bezeichnet, die einen einheitlichen und kontrollierten Zugriff auf Dokumente in Organisationen sicherstellen sollen. Während noch vor weniger als zehn Jahren Data Warehouse nachgerade als technologische Grundlage der Informationserfassung und Informationssuche und damit für nahezu alle Wissensmanagementsysteme galt, rückt deren Bedeutung durch die Googlisierung der (digitalen) Welt, die Bedeutung sozialer Netze und die generelle Entwicklung von starren Taxonomien hin zu flexiblen Folksonomien in den Hintergrund. Von Maur, Schelp und Winter (2003, S. 12) fassen nach Befragung von deutschen und schweizerischen Großunternehmen die aktuelle dringlichen Fragen einer Data Warehouse Lösung in einigen wesentlichen Fragen zusammen:
- Inwieweit kann überhaupt noch strikt zwischen dem analytisch-dispositiven Informationssystem und der operativen Welt unterschieden, wo doch immer mehr Applikation Verbindungen zwischen Datenanalyse und Datenerzeugung schaffen?
- Welche Metadaten müssen erfasst und ausgewertet werden?
- Inwieweit können Suchfunktionen über die grenzen des Data Warehouse hinweg implementiert werden?
- Wie können Data Warehouse Lösungen dauerhaft dynamisch gestaltet werden, ohne einen Ist-Zustand festzuschreiben?
- Wie können Dokumenten Management Systeme integriert werden?
Data Warehouse Lösungen sind in besonders sicherheitsrelevanten und daher notwendigerweise isolierten Informationsräumen wie z.B. das Data Processing für Inter-Banken-Transaktionen und generell bei Großunternehmen im Einsatz. Die sehr aufwendige Entwicklung und Implementierung lassen Data Warehouse als System für den Mittelstand wenig sinnvoll erscheinen. Die Aufgabe von Data Warehouse ist es interne und externe Informationen zusammenzuführen und auszuwerten. Dabei sollen hier vor allem große Datenbestände analysiert und quantitativ ausgewertet werden. Zur Lösung des gesamten Analyse- und Auswertungsprozesses dient, analog zur einheitlichen Datenbasis der operativen Systeme, eine einheitliche Datenbasis zur Entscheidungsunterstützung, das Data Warehouse. Die relevanten Daten der operativen Datenbasen werden extrahiert, bereinigt, vereinheitlicht und geladen. Welche Daten Inhalt des Data Warehouse werden, bestimmt sich einerseits durch den Informationsbedarf der Anwender, andererseits durch die Inhalte der verfügbaren Datenquellen. Demzufolge ist der entscheidende Punkt des Data Warehouse, welche Daten gelagert werden und wie diese Daten systematisch geordnet sind.
Dabei können Waren in einem herkömmlichen Lager lediglich einfach nach unterschiedlichen Kriterien sortiert sein, solange es sich um materielle Waren handelt. Datenbankverwaltungssysteme bieten jedoch durchaus die Möglichkeit, sowohl logisch durch Sichten als auch physisch mehrere Ordnungen bzw. Sortierungen parallel anzubieten. Der Interessenkonflikt, der durch die nicht-komplemetären Bedürfnisse der unterschiedlichen Anwender bzw. Erfordernisse bedingt wird, kann infolgedessen gemindert werden.
Wird Wissen zur Problemlösung bzw. zur Entscheidungsunterstützung benötigt, gibt es prinzipiell nur zwei Möglichkeiten: Eine bessere Strukturierung, also Ordnung der Daten oder eine bessere und schnellere Suchfunktion im Datenbestand. Das Data-Warehouse-Konzept verfolgt primär das erste Ziel und muss daher technisch und konzeptionell dazu in der Lage eine Großzahl an Information zu klassifizieren und zu strukturieren. So genannte Data-Mining-Tools setzen ihren Schwerpunkt auf das Suchen, erzeugen dann allerdings durch die Wissensgenerierung neue Strukturen. Geschäftssemantik und Metadaten bekommen hierbei besonderes Gewicht. Es entsteht eine rekonziliierte Datenbasis, die als Datenquelle für alle Arten von Front-Ends dient. Diese rekonziliierte Datenbasis schafft für die Anwender die Möglichkeit auf Daten eigenständig zuzugreifen und mit unterschiedlichen Front-Ends zu arbeiten.
In die Richtung von Management-Informationssysteme gehen ergänzende Lösungen, die es ermöglichen aus einer großen Menge von betriebsinternen Daten z.B. Verkaufszahlen oder Prozesszeitdaten Übersichten zu spezifischen Kennzahlen zu erhalten. Einige Systeme sind auch in der Lage, auf auffällige Veränderungen automatisch hinzuweisen. Häufig sind in den sehr komplexen Lösungen auch Elemente der Kommunikation, Kalkulation sowie der Terminplanung und -visualisierung beigeordnet oder es bestehen Schnittstellen zu Warenwirtschaftssystemen. Es entstehen immer komplexere integrierte betriebliche Informationssysteme, die als Administrations- und Dispositionssysteme, im Produktionsbetrieb als Produktionsplanungs- und -steuerungssysteme (PPS), im Handelsbetrieb als Warenwirtschaftssysteme (WWS) und neuerdings als Enterprise Resource Planing Systems (ERP) bezeichnet werden. Auch darüber hinaus gehende Konzepte wie das Computer Integrated Manufacturing (CIM) entstehen, die weitere Komponenten eines Produktionsbetriebes integrieren.
Die Konzeption bei der Entwicklung eines Data Warehouse geht von einer zentralen Informationsquelle für alle geschäftlichen Prozesse aus. Aus den bestehenden Systemen werden Daten über einen Import Funktion in die Datenbank importiert und für den Endanwender verdichtet.
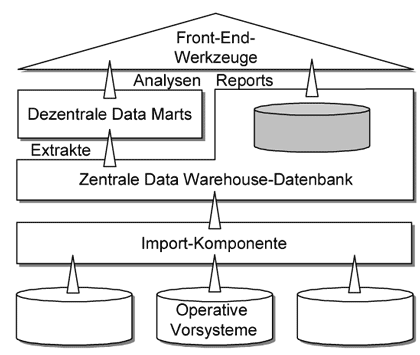
Abb.: Architektur eines Data Warehouse (B?hl 2001. S. 47)
Diese vertikale Vorgehensweise ist unflexibel, zeitaufwendig und durch den Programmieraufwand auch sehr teuer. Durch den Aufbau von so genannten Data Marts wird diesen Schwierigkeiten entgegen gewirkt, indem dezentrale, anwendungsorientierte Applikationen auf der Basis der gemeinsamen Datenbank schnell und günstig auf Basis neuer Technologien wie On-Line Analytical Processing (OLAP) oder Knowledge Discovery in Databases (KDD) aufgebaut werden. (Böhl 2001. S. 47)
Zusammenfassend lässt sich feststellen, dass unter Aspekten des Kosten-Nutzen Vergleichs und wegen der fehlen Flexibilität in Verbindung mit einem erhöhten Grundaufwand Data Warehouse Lösungen für ein Wissensmanagement in der Veranstaltungsbranche wenig sinnvoll erscheinen.

Literatur | Links
- Von Maur, Eitel / Schelp, Joachim / Winter, Robert 2003: Integrierte Informationslogistik. Stand und Entwicklungstendenzen. In: Eitel von Maur und Robert Wagner (Hrsg.): Data Warehouse Management. Das St. Galler Konzept zur ganzheitlich Gestaltung der Informationslogistik. Berlin, Heidelberg: Springer
- Böhl, Jörn 2001: Wissensmanagement in Klein- und mittelständischen Unternehmen der Einzel- und Kleinserienfertigung. München: Herbert Utz Verlag